Blue-Green Deployments: Your Ticket to Stress-Free Software Releases
Discover How to Achieve Zero Downtime, Easy Rollbacks, and Confident Releases with Our Comprehensive Blue-Green Kubernetes Deployment Guide

I'm Farzam, a Software Engineer specializing in backend development. My mission: Collaborate, share proven tricks, and help you avoid the pricey surprises I've encountered along the way.
Introduction: The Art of Painless Deployments
Howdy! I'm back with some fresh insights and experiences to share. This time, we're diving deep into the world of release deployments, with a special focus on a strategy that might just revolutionize your approach: Blue-Green deployments.
Blue-green deployment is a release strategy used in software development to reduce downtime and risk during updates.
Source: Blue-Green Deployment

But wait, there's more! I'm not flying solo on this mission. My trusty wingman and team lead extraordinaire, Jaime Valencia, has joined forces with me to bring you this piece. Why, you ask? Well, we didn't just theorize about this strategy – we rolled up our sleeves, designed it, and implemented it in our own organization. And let me tell you, the benefits were so mind-blowing that we couldn't keep this knowledge to ourselves!

By going through the entire lifecycle of developing and implementing this strategy, we gained invaluable insights into its advantages, challenges, and important considerations. In the end, we completely transformed our deployment process, making life easier not just for ourselves, but for all teams involved in deployments. Oh, and did I mention we also supercharged the overall quality of our deliveries?
Now, I know what you're thinking: "Blue-Green deployments? That's not exactly breaking news!" And you're right. If you Google it right now, you'll find a smorgasbord of examples and implementations. But here's the kicker – most of them feel like they're missing something. They're often tailored for individual projects, showing you how to leverage specific containerization features or orchestration mechanisms to achieve a so-called Blue-Green strategy.
For us, the real challenge wasn't implementing this strategy for individual projects. No, no, no. Our Mount Everest was implementing a strategy that could cover our entire project ecosystem. We're talking about deploying multiple interconnected services together and creating a complete isolated testing environment – all without disturbing a single hair on your real users' heads.
So, buckle up! We're about to show you how to set up a Blue-Green release deployment strategy for your entire project suite. We'll walk you through deploying multiple interconnected services together, creating a completely isolated testing environment, and doing it all without your real users even noticing. This approach doesn't just let you test and validate your upcoming production release – it gives you the luxury of time to address any issues that pop up in testing, well ahead of your production release due date.
Is This for Me? Why Should I Keep Reading?
Let's play a quick game of "Does This Sound Familiar?":
Do your software releases sometimes feel like you're defusing a bomb while blindfolded?
Have you ever wished for just a little more time to test your changes in staging, convinced it would save you a ton of stress and trouble?
Does it seem like no matter how hard you try, you just can't create an environment that truly mimics production?
Do you break out in a cold sweat every time you hear the words "deployment day"?
If you nodded your head to even one of these, then congratulations (or condolences?) – this article is definitely for you! And even if you're sitting there thinking, "Nah, my deployments are smooth as butter," I'd still encourage you to read on. Who knows? You might pick up a new trick or two, or at the very least, learn some fancy new deployment lingo to impress your colleagues at the next standup.

Benefits: What's In It for Me?
Alright, let's cut to the chase. Here's what you stand to gain by implementing a Blue-Green deployment strategy:
Zero User Impact: Your users won't even know you're updating. It's like changing the tires on a moving car, but way less dangerous.
Zero Downtime: As soon as your new version is ready, traffic starts flowing to it immediately. It's like teleportation, but for your software.
Multi-Release Flexibility: If your new deployment turns out to be a dud, no worries! You can redeploy a new version or wipe the slate clean without affecting a single user in your live environment. It's like having a time machine for your deployments.
Stable and Secure Releases: By keeping your Beta environment separate from Live services, you can test thoroughly and securely. It's like having a safety net, a bulletproof vest, and a lucky charm all rolled into one.
Efficient Management: You're in the driver's seat when it comes to how and when changes are promoted from Beta to Live. It's like being the air traffic controller for your software releases.
Flexible Deployment Scheduling: Deploy to your Beta environment anytime, independent of your Live service schedule. Test and verify to your heart's content, well ahead of your live deployment date. It's like rehearsing for a play with an infinitely patient audience.
Challenge: If It Was That Easy, Everyone Would Be Doing It
Now, I know what you're thinking: "This sounds too good to be true!" And you're right to be skeptical. Implementing a Blue-Green deployment strategy isn't without its challenges. Let's take a look at some of the hurdles you might face:
Shared Services: The Isolation Conundrum
One of the main challenges in preparing an isolated beta environment is, well, isolating all the services in the environment. The fewer shared services you have, the more isolated your beta environment becomes.
Take your system's message broker, for example. To isolate its communication solely to beta components, you need to allocate one exclusively for your beta resources. The same process applies to other shared services. Create separate ones for beta where you can and set your beta resources to use them instead of the production ones.
Once your beta environment is ready for promotion to live, you can bid farewell to these temporary services. We'll discuss the creation and removal process further under 'Ensuring consistent configuration across both environments' below.
It's important to note that some resources can't be easily created just for the sake of beta environment isolation. Even if they could be, integrating them into the beta resources isn't always straightforward. A common example is a database. This is where you need to consider your options carefully. If you decide to share them between both live and beta, do so with proper planning and precautions in mind.
Near-Zero Downtime: The Quest for Seamlessness
While zero-downtime is the holy grail, the reality is that there's potential for brief service interruptions during the transition, depending on your configuration. You'll need to customize your setup based on your specific needs and the tools you're using.
If you take away one thing from this entire blog regarding Blue-Green deployments, let it be this: implementing the Blue-Green strategy isn't the toughest part – it's refining it to the point of seamless deployment that's the real challenge.
Forward/Backward Compatibility: The Time-Traveler's Dilemma
Managing database schema changes and migrations is another significant challenge. You and your team must always keep forward and backward compatibility in mind when making changes. This is particularly crucial when it comes to database changes.
Forward compatibility: A system's ability to accept input intended for a future version of itself without breaking.
Backward compatibility: A system's ability to work with input from an older version of itself.
In database contexts:
Forward: Schemas that can handle new fields added in future versions.
Backward: New schema changes that don't break existing queries or data structures.
Maintaining both types of compatibility allows for smoother system evolution and reduces risks during updates or migrations.
Rollback Procedures: The "Oops" Button
A contingency rollback plan must be in place in case of emergency. This can pose a challenge if the Blue-Green strategy you employ is only prepared to deploy forward. It's like having an ejector seat in your car – you hope you never have to use it, but you'll be glad it's there if you need it.
Ensuring Consistent Configuration: The Clone Wars
This is mainly an issue if you're not already using Infrastructure as Code (IaC). There's no doubt it's a learning curve, but to implement a Blue-Green strategy, I'd strongly advise you to invest the time. Once you set up one environment for deployment via IaC, you can mirror it by refactoring it into a template equivalent and use it for both Beta and Live deployment.
The best part? Your releases will always be uniform! It's a huge gain! Plus, it's great to add IaC to your toolbelt if you haven't already!
Increased Infrastructure and Hosting Costs: The Price of Peace of Mind
You will have to maintain two full production environments simultaneously when both beta and live are up, there's no doubt about that. But given the benefits, I can promise you that any manager or higher-up who needs to approve your proposal will dive in headfirst when you show them the advantages. Nothing beats peace of mind, especially for the bigwigs. (Just kidding... sort of.)
Implementation: Enough, You've Sold It, Show Me How!
If you've read this far, then buckle up – you're in for a ride! First, we'll show you a few different methods of implementation. Then, we'll walk you through our approach. If you're in a hurry, you can check out the repository here: blue-green-with-k8s. The README there contains all the commands needed to quickly set up this deployment strategy.
Implementation Methods: How Many Ways Are There?
We personally implemented this strategy in two different methods before creating this third one for you.
Services Based Approach - As a Unit
Our first implementation, which was really our introduction to Blue-Green deployments, revolved around our application's search functionality. We revamped our entire release deployment process and reduced its outage and preparation time by implementing a Blue-Green strategy for our Search Engine and its related services. We focused solely on three interconnected services, creating those 3 services as one unit (aka color) together.
In this approach, we would deploy an Azure Search Service (Azure's Search Engine service), a custom event-driven, container-based Search Engine indexer, and a Job Scheduler service that managed both the Azure Search Service and the custom indexer. Each new deployment would create this unit of resources as a new color.
This was our introduction to the potential of Blue-Green deployments!
Entire Project Suite - Individual Yet Interconnected with Azure Container Apps
Leveraging the knowledge gained in our first implementation, we implemented a similar approach for an entire new project suite that we got to work on and experiment with.
This time, we leveraged Azure Container Apps for Blue/Green version management. We would deploy new beta revisions to existing containers, to co-exist alongside stable revisions in use by users. This leverages the multi-revision feature of Azure Container Apps to allow us to have two revisions simultaneously in action. However, by always redirecting traffic solely to the Live aka Stable revision, live users only interacted with the Stable version of our applications. At the same time, we were able to test our Beta version!
This implementation was more intricate, and if you're planning to implement blue-green for your project suite in production, chances are something like this will be more appropriate for you, especially if you use or plan on using Azure Container Apps. A basic implementation can be found in Microsoft Docs here: Blue-Green Deployment in Azure Container Apps. I'd strongly suggest you use that solely for introductory purposes only. For a real implementation, make sure to test thoroughly and customize based on your needs.
It's worth noting that this implementation is on my todo list as well, which I'll be working on later.
Entire Project Suite - Individual Yet Interconnected with Kubernetes
This is the new implementation that we'll be walking you through today. A step-by-step implementation of a Blue-Green strategy via Kubernetes with three services: a database, a frontend UI service, and a backend API service.
The next section describes the step-by-step implementation.
Step-By-Step Implementation: Show Me the Money!
We'll be deploying a suite of projects using Blue-Green deployment. In our example, we will first deploy a stable version, which will be our initial live deployment. Then, we'll make some small changes in a separate branch and deploy that as our Beta version. Once we see them side by side, both in use and action, we'll then promote our Beta to Live, emulating a real production deployment. In our example, the database will remain shared between both live and beta services, while the frontend and backend services will be created anew for each version.
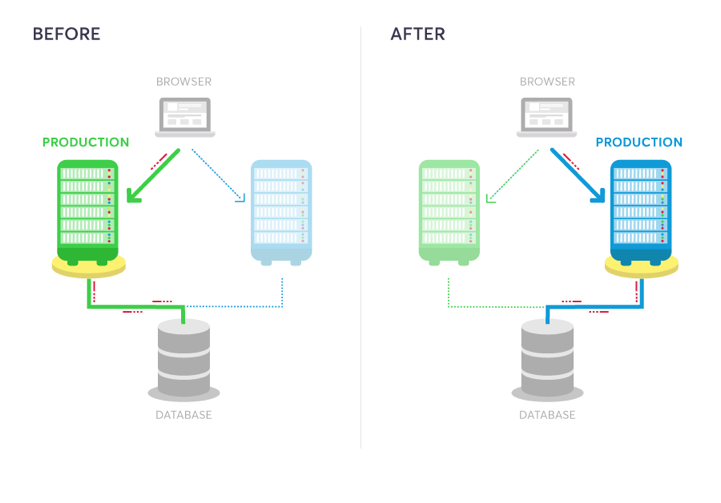
To help visualize this process, let's look at a simplified illustration of our Blue-Green deployment strategy:

Source: Blue-Green Deployment
This diagram shows how user traffic is initially directed to the "blue" (stable) environment. Once we're confident in our beta version, we can seamlessly switch traffic to the "green" (beta) environment, which then becomes our new stable version.
We've prepared all the steps for you and consolidated the deployment into one script. First, I'll walk you through our services. Then I'll show our deployment Kubernetes configuration files to see what we're deploying. Finally, I'll walk you through the actual deployment process. This is where we'll examine our implementation of Blue-Green and see for ourselves on our local machine how easy it is to get started!
The database has two tables:
Greetings
Farewells
First, we'll deploy our stable (starting) version of the services which retrieve and display the first record it finds in our Greetings table.
Then, emulating a feature version in a separate branch, we revise our backend and frontend services to also retrieve and display the first record it finds in the Farewells table, alongside the Greetings table.
After deploying our feature branch, we'll see the simultaneous deployment results first hand, and together, promote the feature branch (aka Beta environment) to our Live environment, overriding the initial version that solely displayed the first Greetings record.
Assumptions
I'm assuming you're familiar with the following technologies. If not, don't worry! A quick Google search should get you up to speed. If I can learn it, it'll be a piece of cake for you!
Bash Scripting
Kubernetes
Docker
- Make sure to enable the Docker Kubernetes cluster
YAML
Step 1: Creation of Dockerfiles
Containerization of your services is a vital step that cannot be bypassed. If containerization is new to you, you're in for a treat. Get busy learning it right now because it's a must-have in your toolbelt.
We created two Dockerfiles for our frontend and backend services. Nothing fancy about them – they containerize our backend and frontend services in the simplest manner possible.
Backend: Dockerfile
Frontend: Dockerfile
Our database is MariaDB, an open-source database that's already available on Docker Hub, where we can simply pull and deploy it from. Shoutout to all the open-source contributors out there. You rock!
Step 1.1: Automating Image Preparation with build-images Bash Script
For MariaDB, since the image is already available on Docker Hub, all we need to do is include the image path in our Kubernetes configuration file, which you'll see in the next step. However, for our own backend and frontend services, we must prepare and build them ourselves.
For building our backend and frontend images, we've created an automated bash script: build-images.sh. This script will be utilized in our deployment-manager script later on, to build, tag, and push our images to our local Docker instance using random tags.
Step 2: Creation of Kubernetes Config Files
Our standard method of operation is to first create default deployment files. These will allow us to test our default non-Blue-Green deployments well before creating a template file to use for Blue-Green deployments.
Here are the default non-template deployment files:
Backend: backend.yaml
Frontend: frontend.yaml
Database: db.yaml
Explanation
Backend & Frontend
For both our backend and frontend services, we create two Kubernetes resources:
Deployment: This resource manages the creation and scaling of pods running our application.
Service: This resource exposes our deployment, making it accessible both within the cluster and externally.
These are configured as follows:
Backend: Internally accessible at port 8080, externally at port 30001
Frontend: Internally accessible at port 3000, externally at port 30002
This setup allows our services to communicate internally and be accessible from the outside world.
By creating these non-template files first, we can thoroughly test our basic setup before moving on to the more complex Blue-Green deployment configuration.
Database
For our database, we've created a more complex setup using MariaDB. Here's a breakdown of the resources:
ConfigMap (mariadb-init): This contains our SQL initialization script. It creates our
blue_greendatabase and sets up two tables:greetingsandfarewells, each populated with one record.PersistentVolumeClaim: This requests 300MB of storage for our database, ensuring data persistence across pod restarts.
Service: This exposes our MariaDB internally and externally:
Internal port: 3306
NodePort (external access): 30306
Deployment: This deploys our MariaDB container:
Uses MariaDB version 11.4
Sets up environment variables for the root password
Mounts volumes for data persistence and initialization
The initialization script (in the ConfigMap) runs on database creation, setting up our required schema:
CREATE DATABASE IF NOT EXISTS blue_green;
USE blue_green;
CREATE TABLE IF NOT EXISTS greetings (
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
greeting VARCHAR(100)
);
INSERT INTO greetings (greeting) VALUES ('hello, hi, how are yah?');
CREATE TABLE IF NOT EXISTS farewells (
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
farewell VARCHAR(100)
);
INSERT INTO farewells (farewell) VALUES ('adios, good bye, see yah?');
In short, we take care of the entire database creation, preparation, and setup in this deployment file. Absolutely no future changes are needed, allowing us to focus on learning the deployment processes instead of getting bogged down with database setup that's not relevant to our main goal.
Step 3: Creation of Kubernetes Config Templates from Config Files
Since only one version of the database will be deployed, there's no need to create a database Kubernetes configuration template file. However, since we are deploying the backend and the frontend dynamically, we will need to leverage the benefits a template provides for the corresponding Kubernetes configuration files.
Backend: backend.yaml.template
Frontend: frontend.yaml.template
Explanation
Backend
We add a {{STATUS}} variable that gets overwritten by our deployment type, i.e., beta or stable.
We replace the image tag with {{IMAGE_TAG}}, which will be overwritten by the randomly generated image tags we'll be creating for our beta and live services.
Frontend
Similar to the backend, we add {{STATUS}} and {{IMAGE_TAG}}, that override the deployment type and the image tag respectively.
For the frontend, however, we also added a ConfigMap that overrides our frontend's runtime environment variable. This overrides the {{BACKEND_NODE_PORT}} and dynamically sets the API URL that the frontend will be pointing to.
apiVersion: v1
kind: ConfigMap
metadata:
name: frontend-config-{{STATUS}}
labels:
app: b-g
component: frontend
status: {{STATUS}}
data:
config.js: |
window.RUNTIME_CONFIG = {
API_URL: "http://localhost:{{BACKEND_NODE_PORT}}",
};
Step 4: Deployment of Live Services (Starting Point - First Stable Deployment)
Execution
From this step onward, we'll be using the deploy-manager bash script that automates our entire deployment process. We'll explain every single step to make sure you grasp its processes in depth as we go along.
To get started, make sure to have Docker running, with the Kubernetes cluster enabled. You must also have the ability to run bash scripts, for which plenty of documentation already exists.
At the root of our blue-green-with-k8s repo, we run the following command to deploy our Live services:
./deploy-manager.sh deploy stable
Result
The output will look something like this, with randomly allocated URLs where we can access our services on our local machine:
==============================
Current Deployment Status
==============================
NAME READY UP-TO-DATE AVAILABLE AGE
b-g-backend-stable 1/1 1 1 2m13s
b-g-frontend-stable 1/1 1 1 2m11s
b-g-mariadb 1/1 1 1 2m14s
--- Current Services ---
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
AGE
b-g-backend-service-stable NodePort 10.104.19.168 <none> 8080:30
951/TCP 2m13s
b-g-frontend-service-stable NodePort 10.100.205.149 <none> 3000:30
183/TCP 2m11s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP
7m27s
mariadb-service NodePort 10.109.117.1 <none> 3306:30
306/TCP 2m14s
--- Access URLs ---
Stable Backend: localhost:31543
Stable Frontend: localhost:32693
MariaDB: localhost:30306
Stable Environment Visualization
When we access the stable frontend URL (in this case, localhost:32693), we see the following:
- A "Greeting" section displaying: "hello, hi, how are yah?"
If we access the stable backend URLs directly, we see:
- At the /greeting endpoint (localhost:31543/greeting): "hello, hi, how are yah?"
This demonstrates that our stable version is correctly retrieving and displaying the greeting message from the database.
Explanation
The ./deploy-manager.sh deploy stable command will trigger the following flow in the script:
deploy)
if [ "$#" -ne 2 ] || [[ ! "$2" =~ ^(stable|beta)$ ]]; then
print_error "Usage: $0 deploy <stable|beta>"
show_exit_prompt
fi
handle_deployment "$2"
;;
This calls the handle_deployment function to deploy our live services. The function looks like this:
handle_deployment() {
local deployment_type=$1
local tag=$(generate_random_tag)
build_images "$tag"
deploy_db
deploy "$deployment_type" "$tag"
check_env "$deployment_type"
}
First, it creates two variables:
deployment_type, which is being set tostabletag, a randomly generated string to be used as our image tag
Then, we build, tag, and push our backend and frontend images using the build_images "$tag" command, which uses our automated build-images bash script. This overrides the tag for both images to this new randomly generated one.
readonly BUILD_SCRIPT="./build-images.sh"
build_images() {
local tag=$1
if [[ ! -x "$BUILD_SCRIPT" ]]; then
chmod +x "$BUILD_SCRIPT"
fi
print_header "Building Images"
print_info "Building images with tag: $tag"
"$BUILD_SCRIPT" true "$tag"
print_success "Images successfully built with tag: $tag"
}
Next, we deploy the database using the deploy_db function, which deploys our db.yaml via the Kubernetes CLI. It waits until the database status becomes ready.
readonly DB_DEPLOYMENT="./deployments/local/db.yaml"
deploy_db() {
print_header "Deploying Database"
kubectl apply -f "$DB_DEPLOYMENT"
print_info "Waiting for Database to be fully ready..."
if kubectl wait --for=condition=ready --timeout=60s pod -l app=b-g,component=mariadb; then
print_success "Database is ready!"
else
print_error "Database is not ready. Please check the deployment."
show_exit_prompt
fi
}
Finally, we deploy our backend and frontend services, using backend.yaml.template and frontend.yaml.template using the deploy() function. We pass our deployment type (stable) and a randomly generated image tag. This is where the magic happens! It's a bit verbose for debugging and UX sake, but still easy to follow.
readonly BACKEND_TEMPLATE="./deployments/local/backend.yaml.template"
readonly FRONTEND_TEMPLATE="./deployments/local/frontend.yaml.template"
Deploy() {
local status=$1
local image_tag=$2
print_header "Deploying $status Environment"
print_subheader "Deploying $status backend"
sed -e "s/{{STATUS}}/$status/g" -e "s/{{IMAGE_TAG}}/$image_tag/g" "$BACKEND_TEMPLATE" | kubectl apply -f -
print_info "Waiting for $status backend deployment to be available..."
if ! kubectl wait --for=condition=available --timeout=60s deployment/b-g-backend-$status; then
print_error "Backend deployment failed. Check the logs for more information."
kubectl get pods -l app=b-g,component=backend,status=$status
kubectl describe deployment b-g-backend-$status
show_exit_prompt
fi
local service_name="b-g-backend-service-$status"
print_info "Checking if $status backend service exists..."
if kubectl get service "$service_name" &>/dev/null; then
print_success "$status backend service exists."
else
print_error "Backend service $service_name does not exist. Check the configuration."
show_exit_prompt
fi
local backend_node_port=$(kubectl get service "$service_name" -o jsonpath='{.spec.ports[0].nodePort}')
print_subheader "Deploying $status frontend"
sed -e "s/{{STATUS}}/$status/g" -e "s/{{IMAGE_TAG}}/$image_tag/g" -e "s/{{BACKEND_NODE_PORT}}/$backend_node_port/g" "$FRONTEND_TEMPLATE" | kubectl apply -f -
print_info "Waiting for $status frontend deployment to be available..."
if ! kubectl wait --for=condition=available --timeout=60s deployment/b-g-frontend-$status; then
print_error "Frontend deployment failed. Check the logs for more information."
kubectl get pods -l app=b-g,component=frontend,status=$status
kubectl describe deployment b-g-frontend-$status
show_exit_prompt
fi
print_success "$status deployment updated with image tag: $image_tag"
print_info "Frontend configured to use backend at http://localhost:$backend_node_port"
}
In this function, we first deploy the backend template with stable status using the following line:
sed -e "s/{{STATUS}}/$status/g" -e "s/{{IMAGE_TAG}}/$image_tag/g" "$BACKEND_TEMPLATE" | kubectl apply -f -
The usage of status and image tag can be seen in the template.
Backend: backend.yaml.template
In short, the status is being used as an identifier to indicate which type of environment the backend service will be. In this case, it's stable, which denotes our Live environment. The image tag is of course being used to pull the version of backend service we want to deploy.
We then await the backend service's deployment until it becomes available. Once available, we retrieve its access port. We will use this value to override our frontend service's environment settings to ensure it's pointing to the correct service.
Next, we repeat the same steps, this time for our frontend service via the following line:
sed -e "s/{{STATUS}}/$status/g" -e "s/{{IMAGE_TAG}}/$image_tag/g" -e "s/{{BACKEND_NODE_PORT}}/$backend_node_port/g" "$FRONTEND_TEMPLATE" | kubectl apply -f -
This time, we not only pass the deployment status and frontend service image tag but also pass the backend node port so that our frontend service can access our backend.
We once again wait until the deployment of frontend services is complete and becomes available.
Once all services are successfully created, the script ends by running a status check using the show_status function. The function uses the Kubernetes CLI (kubectl) to get and display the status of the resources we deployed, as well as their ports.
show_status() {
print_header "Current Deployment Status"
kubectl get deployments
print_subheader "Current Services"
kubectl get services
print_subheader "Access URLs"
local services=("b-g-backend-service-stable" "b-g-backend-service-beta" "b-g-frontend-service-stable" "b-g-frontend-service-beta" "mariadb-service")
local names=("Stable Backend" "Beta Backend" "Stable Frontend" "Beta Frontend" "MariaDB")
for i in "${!services[@]}"; do
local port=$(kubectl get service ${services[$i]} -o jsonpath='{.spec.ports[0].nodePort}' 2>/dev/null)
if [ -n "$port" ]; then
print_info "${names[$i]}: http://localhost:$port"
fi
done
}
And there you have it! That's how we deploy our Live services. In the next part, we'll look at deploying our Beta services and promoting them to Live.
Step 5: Deployment of Beta Services (New Feature)
Execution
To deploy a new version of our services for a better demonstration of the promotion process, we've created a separate branch with additional changes on top of our Live services to emulate a new version deployment.
First, switch from the main branch to feat/display-farewell, then we once again repeat the steps we did in the previous Deployment of Live services step. The only difference is that we have to pass the beta argument instead of stable when running the deploy-manager script.
./deploy-manager.sh deploy beta
Result
The output this time consists of both stable as well as beta services.
==============================
Current Deployment Status
==============================
NAME READY UP-TO-DATE AVAILABLE AGE
b-g-backend-beta 1/1 1 1 5s
b-g-backend-stable 1/1 1 1 2m12s
b-g-frontend-beta 1/1 1 1 2s
b-g-frontend-stable 1/1 1 1 2m9s
b-g-mariadb 1/1 1 1 2m14s
--- Current Services ---
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
AGE
b-g-backend-service-beta NodePort 10.100.39.121 <none> 8080:31
209/TCP 6s
b-g-backend-service-stable NodePort 10.104.191.229 <none> 8080:31
543/TCP 2m13s
b-g-frontend-service-beta NodePort 10.103.147.219 <none> 3000:30
984/TCP 3s
b-g-frontend-service-stable NodePort 10.109.144.9 <none> 3000:32
693/TCP 2m10s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP
5h3m
mariadb-service NodePort 10.109.29.175 <none> 3306:30
306/TCP 2m15s
--- Access URLs ---
Stable Backend: http://localhost:31543
Beta Backend: http://localhost:31209
Stable Frontend: http://localhost:32693
Beta Frontend: http://localhost:30984
MariaDB: http://localhost:30306
We now have two environments running simultaneously in parallel. Each is fully accessible and isolated to its own domain.
Beta Environment Visualization
When we access the beta frontend URL (in this case, localhost:30984), we see the following:
A "Greeting" section displaying: "hello, hi, how are yah?"
A "Farewell" section displaying: "adios, good bye, see yah?"
This demonstrates that our new feature branch has successfully added the farewell message to the frontend.
If we access the beta backend URLs directly, we see:
At the /greeting endpoint (localhost:31209/greeting):
"hello, hi, how are yah?"At the /farewell endpoint (localhost:31209/farewell):
"adios, good bye, see yah?"
These backend responses confirm that our beta version is correctly fetching both the greeting and farewell messages from the database.

Explanation
The exact same processes take place as in the Deployment of Live services step, except a new image is created from our backend and frontend services, which contains the changes we made for our new feature - to retrieve and display not only the greeting but also the farewell from the database.
The services then become available on separate randomly generated URLs for accessing. This isolation allows us to thoroughly test our new feature in the beta environment without affecting the live services that our users are currently accessing.
By comparing the beta and stable versions side by side, we can easily verify that our new feature (adding the farewell message) is working as expected in the beta environment before we decide to promote it to live.
Step 6: Promotion of Beta to Live (Overriding Live Services)
In the real world, this would be where you'd test and validate the deployment of your new changes. At this point, we have two possible paths:
Issues Found In Beta - Redeployment Plan
One of the great perks of the Blue-Green strategy (or at least the way we've implemented it, and you should try to do as well) is that we can deploy new beta services as many times as we want. We can continuously override our Beta environment with new changes without affecting our Live services. All that's needed is to run the same beta deployment command again. It's that easy!
./deploy-manager.sh deploy beta
Validation Successful - Promotion Plan
Execution
If all has gone well in beta validation and you're ready to move forward, we promote our beta services to the Live environment and override it. The deploy-manager script is once again easily capable of handling this via the following command:
./deploy-manager.sh promote
Result
The script once again displays the status of the promotion, as well as the resources we've deployed. This time, however, both the beta and live URLs will display the same content, because at this point, the initial Live services have been overwritten with Beta changes.
Explanation
The promote argument triggers the following flow:
promote)
print_header "Promoting Beta to Stable"
beta_image=$(kubectl get deployment b-g-backend-beta -o jsonpath='{.spec.template.spec.containers[0].image}')
deploy "stable" "${beta_image##*:}" # Extract tag from image
print_success "Beta promoted to stable. New stable image tag: ${beta_image##*:}"
;;
Here, we leverage the Kubernetes CLI (kubectl) to retrieve the image tag we deployed our beta services with. This tag is shared between both the backend and frontend. We then use this tag to call the deploy function using the stable tag, which overwrites the existing Live services with our beta ones. Essentially, we're repeating the Deployment of Live services step but with the beta image tag.
Source: AB Tasty Blog
Step 7: Teardown Beta Services (Finalize Live Deployment & Remove Unused Resources)
Execution
Once again emulating a practical example, this is where we would terminate our unused beta environment to save costs. The deploy-manager script can again be used to manage the teardown.
./deploy-manager.sh teardown beta
Result
Once the teardown of beta resources is complete, all beta resources are removed.
==============================
Tearing down beta resources
==============================
deployment.apps "b-g-backend-beta" deleted
deployment.apps "b-g-frontend-beta" deleted
service "b-g-backend-service-beta" deleted
service "b-g-frontend-service-beta" deleted
configmap "frontend-config-beta" deleted
✔ Beta resources teardown complete.
Explanation
Our deploy-manager script command triggers the following flow:
teardown)
if [ "$#" -ne 2 ] || [[ ! "$2" =~ ^(all|beta)$ ]]; then
print_error "Usage: $0 teardown <all|beta>"
show_exit_prompt
fi
teardown_resources "$2"
;;
This calls the teardown_resources function to remove beta resources.
teardown_resources() {
local scope=$1
if [ "$scope" == "all" ]; then
print_header "Tearing down all resources"
kubectl delete deployment,service,configmap,pvc -l app=b-g
print_success "All resources teardown complete."
elif [ "$scope" == "beta" ]; then
print_header "Tearing down beta resources"
kubectl delete deployment,service,configmap -l app=b-g,status=beta
print_success "Beta resources teardown complete."
}
Step 8: Teardown Live Services (Cleanup)
Execution
And to finalize your local machine cleanup, we run the teardown again, this time terminating Live services as well.
./deploy-manager.sh teardown all
Result
==============================
Tearing down all resources
==============================
deployment.apps "b-g-backend-stable" deleted
deployment.apps "b-g-frontend-stable" deleted
deployment.apps "b-g-mariadb" deleted
service "b-g-backend-service-stable" deleted
service "b-g-frontend-service-stable" deleted
service "mariadb-service" deleted
configmap "frontend-config-stable" deleted
configmap "mariadb-init" deleted
persistentvolumeclaim "mariadb-pv-claim" deleted
✔ All resources teardown complete.
Explanation
Our deploy-manager script command triggers the following flow:
teardown)
if [ "$#" -ne 2 ] || [[ ! "$2" =~ ^(all|beta)$ ]]; then
print_error "Usage: $0 teardown <all|beta>"
show_exit_prompt
fi
teardown_resources "$2"
;;
Except this time, it enters the first condition in our if statement, which removes all blue-green related resources (regardless of environment type), based on resource tagging we did in our Kubernetes configuration files.
teardown_resources() {
local scope=$1
if [ "$scope" == "all" ]; then
print_header "Tearing down all resources"
kubectl delete deployment,service,configmap,pvc -l app=b-g
print_success "All resources teardown complete."
elif [ "$scope" == "beta" ]; then
print_header "Tearing down beta resources"
kubectl delete deployment,service,configmap -l app=b-g,status=beta
print_success "Beta resources teardown complete."
}
And there you have it!

We've successfully implemented, deployed, promoted, and cleaned up our Blue-Green deployment strategy. This approach gives you the flexibility to:
Test new versions of your services in isolation
Promote beta versions to live with minimal downtime
Easily redeploy new beta versions if issues are found during testing
Quickly roll back to the previous stable version if problems arise after promotion
This multi-faceted flexibility is the true power of the Blue-Green deployment strategy, providing a safety net that allows for more confident and agile deployments.
Final Thoughts: Painting Your Deployments Blue and Green
As we wrap up this journey through the land of Blue-Green deployments, let's take a moment to reflect on what we've accomplished. We've not just talked about a deployment strategy – we've implemented it, tested it, and seen its benefits firsthand.
Here are the key takeaways from our Blue-Green adventure:
Reduced Risk: By creating an isolated beta environment, we can thoroughly test new features without affecting live users.
Flexibility: The ability to easily rollback or redeploy gives us unprecedented control over our release process.
Improved User Experience: With near-zero downtime deployments, our users can enjoy uninterrupted service.
Better Testing: The isolated beta environment allows for more comprehensive testing in a production-like setting.
Cost-Effective: While there is an initial increase in resources, the long-term benefits in terms of stability and reduced downtime far outweigh the costs.
Implementing Blue-Green deployments might seem daunting at first, but as we've seen, with the right tools and approach, it's a achievable goal that can revolutionize your deployment process.
Remember, the journey doesn't end here. As you implement this strategy in your own projects, you'll undoubtedly encounter unique challenges and opportunities. Embrace them! Each obstacle is a chance to refine your process and make it even more robust.
So, are you ready to take your deployments to the next level? The blue (or green) sky's the limit!
Happy deploying, and may your releases always be smooth and your downtimes non-existent!



